
Generative Adversarial Networks (GANs) have significantly transformed the field of artificial intelligence, pushing the boundaries of what machines can create. From realistic image synthesis to deepfake technology, GANs have evolved rapidly since their inception. Let’s explore the journey of GANs, their advancements, and their impact on various industries.
Jump to:
What are Generative Adversarial Networks (GANs)?
How do Generative Adversarial Networks work?
Applications of Generative Adversarial Networks (GANs)
Challenges Faced by Generative Adversarial Networks (GANs)
Components of Generative Adversarial Networks Model
Advantage Generative Adversarial Networks (GANs)
The Birth of GANs
GANs were first introduced by Ian Goodfellow and his colleagues in 2014. The core idea behind GANs is the competition between two neural networks: the generator and the discriminator. The generator creates synthetic data, while the discriminator evaluates its authenticity. Over time, the generator improves its ability to create realistic outputs, fooling the discriminator more effectively.
This adversarial process enables GANs to generate highly realistic images, videos, and even textual content, making them a groundbreaking advancement in AI.
What are Generative Adversarial Networks (GANs)?
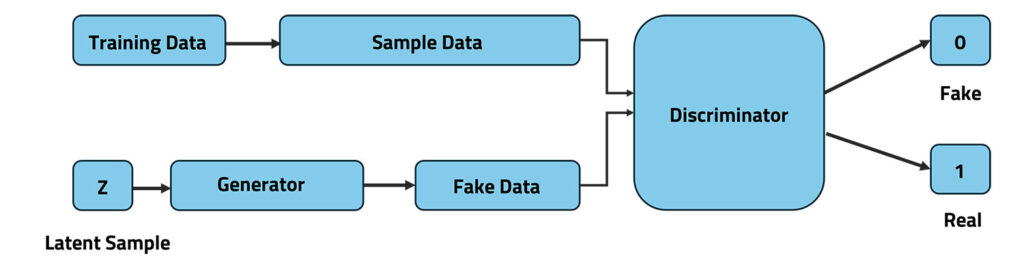
Generative Adversarial Network (GAN) consists of 2 fundamental building blocks the generator and the discriminator. These two networks work together in a competitive way to improve overtime.
The generator creates new data by using random noise. Its goal is to produce data that looks just like real data. On the other hand, the discriminator’s job is to check whether the generated data is real or fake by comparing it with actual data.
During training, the generator keeps trying to fool the discriminator into believing that its generated data is real. Meanwhile, the discriminator keeps improving its ability to tell real data from fake data. As they continue learning from each other, the generator gets better at creating realistic data, and the discriminator becomes stronger at identifying fake ones. This competition helps both networks improve, leading to the generation of highly realistic data.
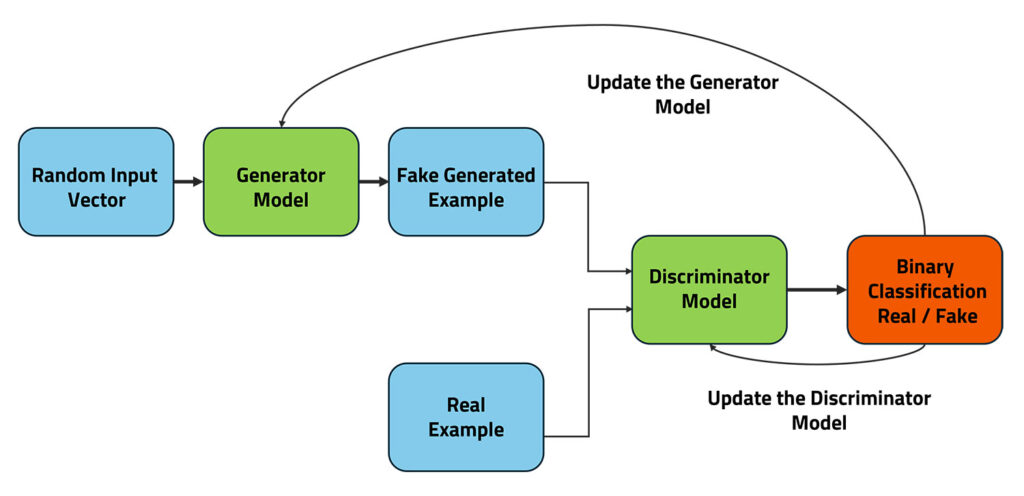
How do Generative Adversarial Networks work?
The way Generative Adversarial Networks (GANs) function is like a strategic game where the success of one player results in failure of the other. The generator starts with random input and gradually improves its ability to create outputs that closely match the distribution of real training data. Meanwhile, the discriminator continuously learns to distinguish between real and generated data with greater accuracy.
Initialization:
At the start, both the generator and the discriminator are initialized with random weights, meaning they have no prior knowledge of the data distribution.
Training Loop:
- The generator produces a batch of synthetic data based on random noise.
- The discriminator evaluates this batch alongside real data from the training set.
- Both networks receive feedback based on their performance—if the discriminator successfully identifies fake data, the generator adjusts to produce more convincing outputs, while the discriminator refines its ability to detect fakes.
Optimization:
The discriminator aims to maximize its accuracy in distinguishing between real and fake data, while the generator strives to minimize the discriminator’s ability to differentiate between the two. This adversarial process continues iteratively, forcing both networks to evolve, resulting in a generator that creates highly realistic data and a discriminator that becomes increasingly sophisticated at detection.
Over time, this competitive dynamic leads to a finely tuned generator capable of producing data that is nearly indistinguishable from real-world samples.
Types of GANs
Generative Adversarial Networks (GANs) come in various types, each designed to address specific challenges or improve performance for different tasks. Here are some of the most common types of GANs:
Vanilla GAN: This is the standard GAN, consisting of a generator and a discriminator trained through adversarial learning. The generator creates data, and the discriminator evaluates it. Both networks improve through competition.
Deep Convolutional GAN (DCGAN): DCGAN uses convolutional layers instead of fully connected layers, making it more effective for generating images. It employs deep learning techniques like batch normalization and LeakyReLU activation to improve stability and quality.
Conditional GAN (cGAN): In a Conditional GAN, both the generator and discriminator receive additional information, such as class labels or specific attributes. This allows for controlled generation of data, such as creating images of specific objects or styles.
Wasserstein GAN (WGAN): WGAN improves training stability by replacing the traditional loss function with the Wasserstein distance. This reduces problems like mode collapse, where the generator produces limited variations of data.
Wasserstein GAN with Gradient Penalty (WGAN-GP): An improved version of WGAN that stabilizes training further by penalizing gradients, ensuring smoother updates and better convergence.
InfoGAN: InfoGAN extends GANs by maximizing the mutual information between generated samples and specific latent variables. This helps in generating interpretable and structured outputs.
Progressive Growing GAN (PGGAN): PGGAN starts with generating small images and gradually increases resolution during training. This technique is used for high-quality image synthesis, such as generating realistic human faces.
CycleGAN: CycleGAN is used for image-to-image translation without needing paired training data. It is effective in applications like converting photos into paintings or translating images between different styles.
StyleGAN: Developed by NVIDIA, StyleGAN introduces a style-based generator that enables fine-grained control over image attributes. It is widely used for generating hyper-realistic human faces.
BigGAN: BigGAN scales up the model size and dataset to generate highly detailed images. It is one of the most powerful GANs for large-scale image generation.
Applications of Generative Adversarial Networks (GANs)
Since GANs can produce high-quality synthetic data, they have found applications in a variety of fields. Among the noteworthy projects are:
Image Generation: Using random noise inputs or textual descriptions, GANs can produce photorealistic images. This capability is demonstrated by projects such as NVIDIA’s StyleGAN and DeepArt.
Video Generating: GANs are used to create video sequences that can replicate events or situations from real life.
Text-to-Image Synthesis: GAN architectures are used by models such as DALL-E to translate textual descriptions into related images.
Data Augmentation: To overcome the problem of sparse datasets, GANs can produce artificial medical pictures for training in domains like as healthcare.
Super Resolution: Low-resolution images are improved by methods like Super Resolution GAN (SRGAN), which make them sharper and more detailed.
Challenges Faced by Generative Adversarial Networks (GANs)
Despite their remarkable potential, GANs have several drawbacks, namely –
Training Instability: Due to GANs’ adversarial nature, training procedures may become unstable, with one network potentially overwhelming the other.
Mode Collapse: This happens when the generator only generates a small number of output types rather than a wide variety.
Hyperparameter Sensitivity: Careful tuning is necessary for the best outcomes because hyperparameter selections can have a substantial impact on GAN performance.
Components of Generative Adversarial Networks Model
Generative Adversarial Networks (GANs) consist of several key components that work together in a competitive manner to generate realistic data.
Generator: The generator is a neural network that creates synthetic data starting from random noise. Its objective is to produce data that closely resembles real samples so that the discriminator cannot distinguish between real and fake data. Over time, it learns to generate increasingly realistic outputs.
Discriminator: The discriminator acts as a classifier that evaluates whether a given input is real (from the actual dataset) or fake (produced by the generator). It learns to recognize patterns in real data and improves its ability to detect fake samples. As the generator gets better, the discriminator also refines its classification skills.
Latent Space (Random Noise Input): The generator starts with random noise as input, which allows it to create diverse and unique outputs. This latent space ensures variability in the generated data rather than simply memorizing training samples.
Loss Function: The loss function measures how well each network is performing. The generator’s loss depends on how successfully it fools the discriminator, while the discriminator’s loss is based on its ability to correctly classify real and fake data. This competitive nature forces both models to improve continuously.
Adversarial Training Process: The generator and discriminator are trained together in an iterative loop. The generator creates fake data, which the discriminator evaluates. If the discriminator correctly identifies fake data, the generator adjusts to improve its realism. If the discriminator gets fooled, it updates itself to become better at detection. This back-and-forth process ensures that both networks are evolving over time.
Optimization Algorithm: Optimization methods, such as Stochastic Gradient Descent (SGD) or the Adam optimizer, are used to adjust the weights of both networks. These algorithms help stabilize training and fine-tune parameters, ensuring that the generator and discriminator improve their performance over iterations.
Feedback Loop: The continuous interaction between the generator and discriminator drives the learning process. As training progresses, the generator produces more realistic data, and the discriminator becomes more accurate at distinguishing real from fake samples. Eventually, the generator creates outputs that are nearly indistinguishable from real-world data.
Advantage Generative Adversarial Networks (GANs)
To get a holistic insight into the concept of GANs, it is essential to learn about their advantages. The advantages of GANs are what enable the approach to stand out in the deep learning realm.
High-Quality Data Generation
GANs produce highly realistic images, videos, and text by learning complex data distributions. They are widely used in generating synthetic images, deepfake technology, and realistic human faces.
Data Augmentation
GANs help in expanding datasets by generating synthetic samples, improving machine learning models’ performance in scenarios where real data is limited, such as medical imaging and speech synthesis.
Improved Unsupervised Learning
GANs excel in unsupervised learning by discovering underlying patterns in unlabeled data. They are used in applications like feature extraction, anomaly detection, and self-supervised learning.
Style Transfer and Image Enhancement
GANs enhance images by improving resolution, removing noise, and generating artistic styles. They are widely used in photo editing, video upscaling, and super-resolution applications.
Adversarial Training for Robustness
GANs improve model robustness by generating adversarial examples that test deep learning models’ vulnerabilities, making AI systems more resilient against attacks and biases.
Generative Adversarial Networks (GANs) Loss Function
Discriminator Loss Function
The discriminator identifies real and fake data using binary cross-entropy loss. It maximizes the probability of correctly classifying real data while minimizing the likelihood of misclassifying generated samples.
Generator Loss Function
The generator’s goal is to fool the discriminator by minimizing its ability to distinguish fake data. It adjusts its parameters to produce increasingly realistic outputs that resemble real data distributions.
Combined Min-Max Optimization
GANs follow a min-max optimization process where the generator minimizes classification errors while the discriminator maximizes accuracy. This adversarial learning improves both networks, leading to highly realistic generated data.
Alternative Loss Functions
Alternative loss functions like LS-GAN, WGAN, and WGAN-GP stabilize training, reduce mode collapse, and enhance generated data quality by improving gradient flow and ensuring smoother convergence during adversarial training.
Implementation in Python (TensorFlow/Keras)
GAN loss functions are implemented using TensorFlow/Keras, defining binary cross-entropy for classification. The generator and discriminator are iteratively optimized to enhance data realism and classification accuracy.
Conclusion
Generative Adversarial Networks represent an innovative development in artificial intelligence and machine learning. We can appreciate their potential in a variety of fields, from medical imaging to creative creation, by knowing what they are and how they work. We may anticipate even more cutting-edge uses for GAN technology in the future as research advances and issues are resolved.
In short, it is evident that these models are changing how we approach the creation of synthetic data and innovative technological applications, whether we are investigating generative adversarial networks projects or elucidating accurate claims about GANs.
FAQs
What is a Generative Adversarial Network (GAN)?
A GAN is a deep learning model with two neural networks generator and discriminator competing to create realistic synthetic data, improving over time through adversarial training.
How are GANs different from other generative models?
Unlike Variational Autoencoders (VAEs) or autoregressive models, GANs use adversarial training, where two networks compete, leading to more realistic and high-quality synthetic data generation.
How long does it take to train a GAN?
GAN training time varies based on model complexity, dataset size, and hardware. It can take hours to weeks, requiring careful tuning for stable convergence and high-quality outputs.
What is the future of GAN technology?
GANs will continue advancing in AI-driven creativity, improving data synthesis, enhancing training stability, and expanding applications in industries like gaming, healthcare, and security.

Abhishek Sharma
Website Developer and SEO Specialist
Abhishek Sharma is a skilled Website Developer, UI Developer, and SEO Specialist, proficient in managing, designing, and developing websites. He excels in creating visually appealing, user-friendly interfaces while optimizing websites for superior search engine performance and online visibility.